事件起因
emmm,事件的产生原因是我把一个ceph N版本的集群写坏了。仅仅进行了很多轮的100线程并发写,然后集群就异常了。


异常清单:
- MDS监控到慢IO,使用
ceph health detail看是node155的问题,重启了node155的MDS后发现node144又出现这个问题,OK,重启node144的MDS。emmm,你特么是在逗我,node155又出现这个问题,反正就是反复横跳呗。🙃 - 显示有一个pg出于
inactive,一个处于incomplete。查看健康状态,哪特么有inactive的pg啊,这异常信息显示的是啥啊。 - 查看osd状态,emmm,异常了三个盘,这异常信息也没有提示,osd那也没有显示具体的信息。
恢复过程
拉起OSD
osd挂掉了嘛当然是重拉osd起来啊。拉啊拉,拉了N次就是起来后持续不到一分钟就down掉。放弃。
拉不起来osd那我就踢掉,于是从此开始了漫长的恢复之路。踢掉OSD后再加进来显示OSD正在rebalance,同时pg出现了13个incomeplete。一开始并没有把整个incomplete当会事,让他恢复呗,持续了3个小时后,所有的PG都正常了,唯独这13个不动了,被踢掉后加进来的pg也再rebalance的状态卡住了。
恢复pg的incomplete
Peering过程中, 由于
a. 无非选出权威日志
b. 通过choose_acting选出的Acting Set后续不足以完成数据修复,导致Peering无非正常完成
找出所有的incomplete的pg
ceph health detail | grep incomplete
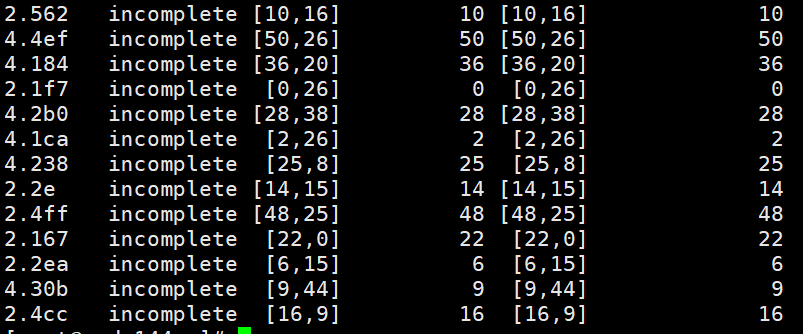
按照网上的说法,incomplete状态系统是无法自己复原的,需要使用ceph-objectstore-tool主动把incomplete标记未complete。
针对每一个pg,stop掉相关的OSD
1systemctl stop ceph-osd@osdid这一步需要在osd所在的node上执行,巨烦!!!!
所以还得提前
ceph osd tree记录下所有的osd分布。把每个出问题的pg涉及到的osd标记complete
1ceph-objectstore-tool --pgid pgidxxx --op mark-complete --data-path /var/lib/ceph/osd/ceph-osdidxxx/ --type bluestore重启被关闭的osd
1systemctl start ceph-osd@id
按照上述步骤可以恢复,如果pg较多手工就比较慢了,不用脚本执行很折磨人。
本以为万事大吉了。呵呵呵呵,还是太年轻。
pg down
恢复到最后,ceph监控状态显示有一个pg down了。
涉事pg-2.1f7,所用的osd4,26。emmm,一切正常啊。这俩osd毫无问题。重启其中的主OSD--无效,重启副本osd--无效。
检查集群的osd状态,what,为嘛 osd.0 是异常的,出问题的pg好像和它没关系啊。拉起试试,拉起后就死掉,得嘞,踢掉添加吧,反正集群已经是坏的了,按照双副本模式,不会出现数据丢失(人啊,不要立flag)。
踢掉再添加后,down掉的pg起来了,完美。出现了一大堆object unfound。潜意识把它们都忽略了,没处理,一直在等待数据迁移完成,直到最后就剩下这大概20000个对象。
反正不怕数据丢失,放弃你们吧。
| |
对每一个出问题的pg执行该命令。
ok~,系统出现backing了,说明在恢复。
持续等待了4个小时,backing完成了。
进入了持续的不知道多久的deep和Scrubbing。
之后看到了久违的HEALTH_OK
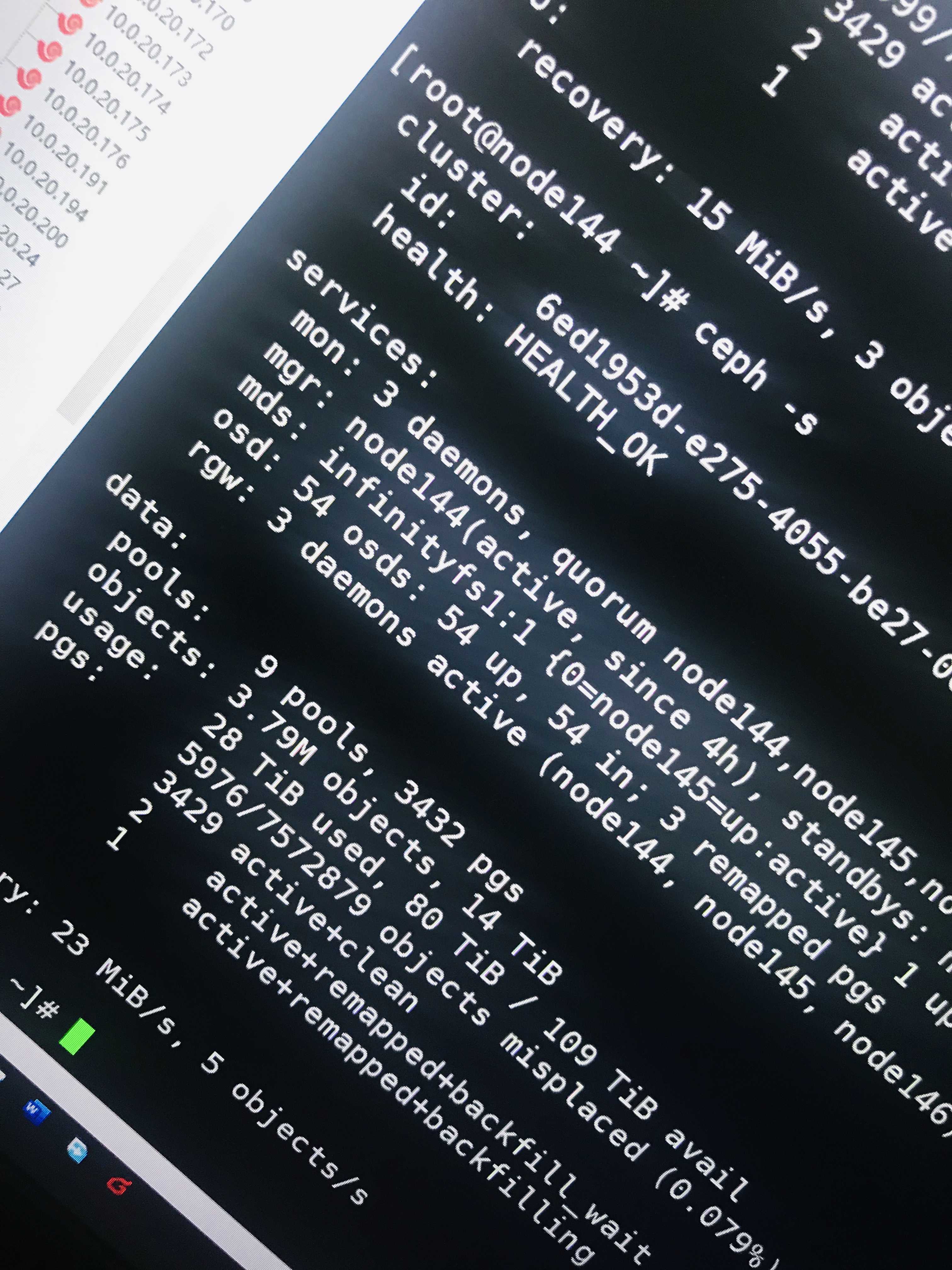
毕竟测试环境,只要不怕数据丢,一块盘一块盘的踢掉再加,一般是不会丢失数据的。